Blog Lab
Aprendizaje Federado: una pieza clave para la protección de datos y la soberanía digital
Equipo de Sherpa
Sherpa.ai es una empresa tecnológica especializada en Inteligencia Artificial privada y segura, con un foco destacado en el Aprendizaje Federado. Su plataforma permite entrenar modelos de IA de forma colaborativa entre distintas organizaciones, dispositivos o entornos, sin necesidad de mover ni centralizar los datos sensibles. De este modo, Sherpa.ai facilita el desarrollo de soluciones avanzadas de IA preservando la privacidad, reduciendo riesgos regulatorios y permitiendo el cumplimiento de marcos como el RGPD.
La tecnología de Sherpa.ai se ha aplicado en ámbitos como salud, industria, defensa y servicios financieros, donde la protección de los datos es especialmente crítica. Su propuesta combina innovación en IA, privacidad por diseño y capacidad de despliegue en entornos reales, ayudando a las organizaciones a aprovechar el valor de sus datos sin comprometer su confidencialidad.
Web: https://sherpa.ai/
Aprendizaje Federado: una pieza clave para la protección de datos y la soberanía digital
La inteligencia artificial vive en la actualidad una fase de aceleración sin precedentes. Desde sistemas de recomendación hasta modelos avanzados de IA generativa, la capacidad de estas tecnologías para transformar sectores económicos y sociales depende, en gran medida, de un elemento fundamental: los datos.
Cuantos más datos —y de mayor calidad— están disponibles para entrenar modelos, mayor es su capacidad para identificar patrones, realizar predicciones precisas y generar valor. En este sentido, los datos se han consolidado como el principal activo estratégico de la economía digital.
Sin embargo, esta creciente dependencia también plantea importantes desafíos. Una parte significativa de estos datos es de carácter personal o sensible, lo que introduce riesgos asociados a su uso, almacenamiento y transferencia. La centralización masiva de información, práctica habitual en muchos enfoques tradicionales de desarrollo de IA, incrementa la exposición a brechas de seguridad, usos indebidos o accesos no autorizados.
En este contexto, la protección de los datos deja de ser un requisito meramente normativo para convertirse en un elemento estructural del diseño de los sistemas de inteligencia artificial. No se trata únicamente de cumplir con marcos regulatorios como el Reglamento General de Protección de Datos (RGPD), sino de garantizar que la innovación tecnológica se desarrolle sobre principios de confianza, seguridad y respeto a los derechos fundamentales.
Este cambio de enfoque está impulsando la adopción de nuevas arquitecturas y paradigmas tecnológicos que integran la privacidad desde su concepción. Entre ellos, el aprendizaje federado destaca como una de las aproximaciones más prometedoras para compatibilizar el aprovechamiento del dato con su protección.
¿Qué es el aprendizaje federado y por qué es relevante?
El aprendizaje federado surge como respuesta a una realidad estructural del ecosistema digital actual: los datos no están centralizados, sino distribuidos en múltiples silos. Organizaciones, instituciones, hospitales, bancos, administraciones públicas y países almacenan grandes volúmenes de información que, en muchos casos, no pueden compartirse ni trasladarse libremente debido a restricciones regulatorias, exigencias de seguridad, obligaciones de confidencialidad, protección de la privacidad o razones competitivas.
En sectores altamente regulados como la salud, las finanzas, la defensa, la energía o las telecomunicaciones, los datos suelen contener información sensible, estratégica o personal. Su movimiento entre entidades, jurisdicciones o infraestructuras puede implicar riesgos legales, operativos y reputacionales, además de aumentar la exposición frente a ciberataques, fugas de información o usos no autorizados. Normativas como el GDPR en Europa, junto con marcos sectoriales y políticas internas de seguridad, limitan de forma estricta cómo, dónde y con quién pueden compartirse los datos.
Esta realidad provoca que una gran parte del conocimiento disponible permanezca infrautilizado. De hecho, según TechRadar*, se estima que más del 80% de los datos generados a nivel global son privados y no están disponibles para su uso en modelos tradicionales de inteligencia artificial. Como consecuencia, muchos modelos se entrenan con una visión parcial de la realidad, basada únicamente en los datos accesibles para una organización concreta. Esta fragmentación limita la precisión, la robustez y la capacidad de generalización de la IA, especialmente en escenarios donde el valor real reside en aprender de múltiples fuentes distribuidas.
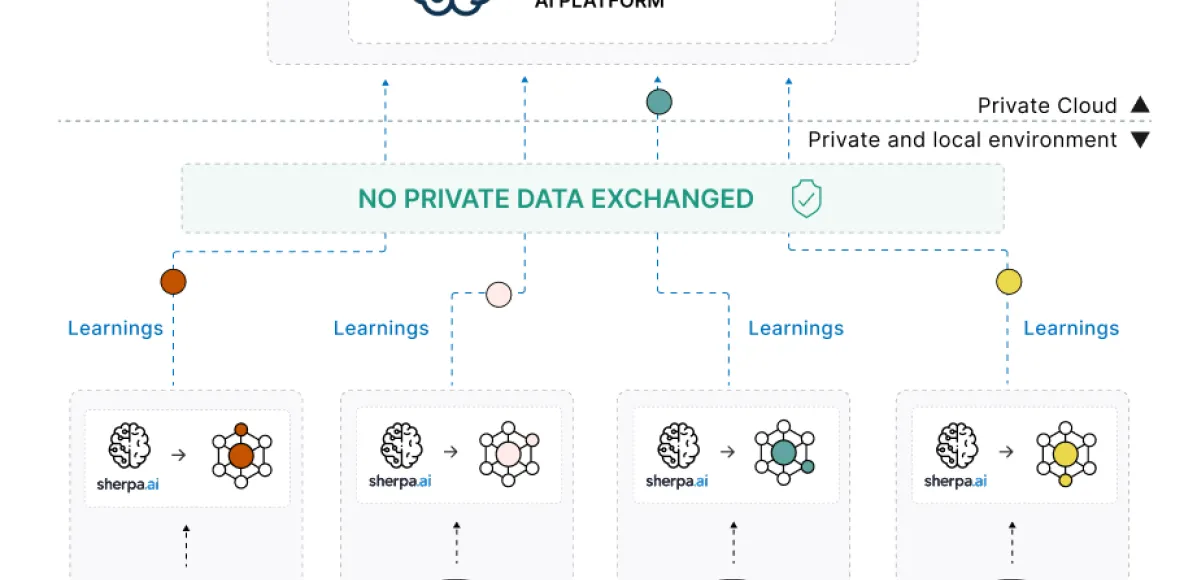
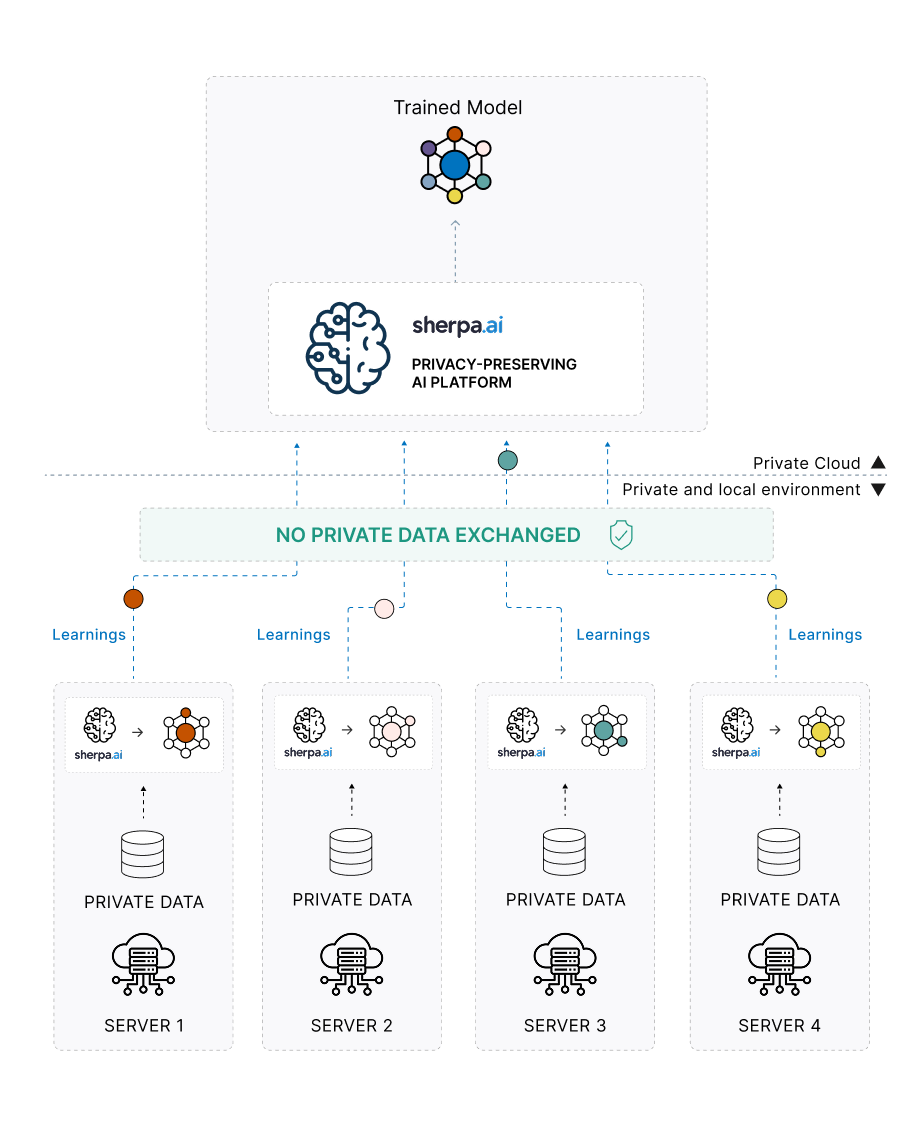
En este contexto, el aprendizaje federado nace como una alternativa que permite aprovechar el valor de los datos allí donde se generan, sin necesidad de trasladarlos, centralizarlos ni exponerlos. Se trata de un enfoque de entrenamiento de modelos de inteligencia artificial en el que los datos permanecen siempre bajo el control de cada organización o entorno de origen. En lugar de compartir los datos, se comparten únicamente parámetros o actualizaciones del modelo, que se agregan de forma segura para construir un modelo global.
De este modo, el aprendizaje federado permite colaborar en el desarrollo de modelos de IA más precisos y representativos, preservando al mismo tiempo la privacidad, la soberanía del dato, el cumplimiento regulatorio y la seguridad de la informaciónTop of FormBottom of Form.
Este enfoque presenta ventajas fundamentales desde el punto de vista de la protección de datos:
- No compartición de datos (mayor privacidad y seguridad): se evita la transferencia masiva de información personal.
- Reducción del riesgo: al no centralizar los datos, se reduce la superficie de ataque. Es decir los datos no son susceptibles de ataque durante las comunicaciones ya que no se comparten
- Mayor control por parte de los titulares de los datos: las organizaciones mantienen la custodia de su información.
- Facilitación del cumplimiento normativo: se alinea con principios clave del RGPD, como privacidad desde el diseño y por defecto.
La importancia del aprendizaje federado en la soberanía digital:
El aprendizaje federado desempeña un papel clave en la soberanía digital porque permite avanzar en inteligencia artificial sin que los propietarios de los datos tengan que perder el control sobre ellos. A diferencia de los enfoques tradicionales, basados en la centralización de grandes volúmenes de información, este modelo permite que cada organización mantenga sus datos en su propio entorno, bajo sus propias políticas de seguridad, gobernanza y cumplimiento normativo.
Esto resulta especialmente relevante en un contexto en el que los datos se han convertido en un activo estratégico. Para muchas organizaciones, compartir o transferir información no solo implica un riesgo de privacidad, sino también una posible pérdida de control sobre conocimiento sensible, ventaja competitiva o información crítica. El aprendizaje federado evita este dilema: los datos no se mueven, no se copian ni se entregan a terceros; permanecen siempre bajo la custodia de quien los genera o los posee.
Al mismo tiempo, este enfoque no impide la colaboración. Al contrario, la hace posible en escenarios donde antes era inviable. Varias organizaciones pueden entrenar conjuntamente modelos de inteligencia artificial más precisos y representativos, aprendiendo de datos distribuidos sin necesidad de compartirlos directamente. Lo que se intercambia son únicamente actualizaciones del modelo, que pueden agregarse de forma segura para construir una inteligencia común sin exponer la información original.
De este modo, el aprendizaje federado refuerza la soberanía digital al combinar dos objetivos que tradicionalmente parecían difíciles de conciliar: mantener el control sobre los datos y, al mismo tiempo, aprovechar su valor colectivo. Cada participante conserva la propiedad, la localización y la gobernanza de su información, mientras contribuye al desarrollo de modelos más avanzados, robustos y útiles.
Este modelo es especialmente importante para sectores y territorios que buscan desarrollar capacidades propias de inteligencia artificial sin depender de infraestructuras centralizadas externas ni transferir datos fuera de su ámbito de control. En el caso de Europa, encaja de forma natural con una visión de IA basada en la privacidad, la seguridad, la cooperación y el respeto a la soberanía del dato.
Casos de uso reales: aprendizaje federado aplicado en salud y finanzas:
1. Diagnóstico de enfermedades raras en entornos hospitalarios
Sherpa.ai ha desplegado su plataforma de aprendizaje federado en proyectos reales del ámbito sanitario, en colaboración con instituciones como el National Institutes of Health (NIH) en Estados Unidos y University College London (UCL) en Reino Unido, con el objetivo de mejorar el diagnóstico de enfermedades raras, como las distrofias relacionadas con colágeno VI (COL6-RD).
El principal reto en este tipo de patologías es la escasez y fragmentación de los datos clínicos, que dificulta el entrenamiento de modelos de inteligencia artificial con capacidad de generalización. Además, la sensibilidad de los datos médicos impone fuertes restricciones a su compartición, especialmente en entornos internacionales.
Para abordar este desafío, Sherpa.ai implementó una arquitectura de aprendizaje federado en la que:
- Los datos clínicos e imágenes permanecen en cada institución.
- Los modelos se entrenan localmente sobre datos propios.
- Las actualizaciones del modelo se agregan de forma segura para construir un modelo global.
Gracias a este enfoque, se lograron resultados significativos:
- Incremento de la precisión diagnóstica superior al 20% respecto a modelos entrenados de forma aislada.
- Mejora en la capacidad de detección de patrones complejos, especialmente en casos límite o poco representados.
- Reducción de los tiempos necesarios para alcanzar modelos clínicamente útiles, al aprovechar datos distribuidos desde el inicio.
Además del impacto técnico, el proyecto permitió:
- Garantizar el cumplimiento de normativas de protección de datos en múltiples jurisdicciones.
- Evitar la transferencia internacional de datos sensibles.
- Establecer un modelo replicable de colaboración entre instituciones sanitarias.
Este caso demuestra cómo el aprendizaje federado no solo mejora los resultados clínicos, sino que habilita una colaboración global sostenible en entornos altamente regulados.
2. Transformación del sector financiero: modelos más precisos sin romper los silos de datos
Sherpa.ai ha trabajado con distintas instituciones financieras europeas e internacionales para implementar aprendizaje federado en casos de uso críticos como la detección de fraude, la optimización de la conversión comercial y la retención de clientes.
El punto de partida en estos proyectos era común: datos altamente fragmentados, tanto a nivel geográfico (distintos países con regulaciones específicas) como organizativo (separación entre banca, seguros y otras unidades de negocio). Esta fragmentación limitaba el rendimiento de los modelos y dificultaba la extracción de valor.
Mediante la plataforma de Sherpa.ai, se habilitó un entorno federado en el que:
- Cada entidad o unidad de negocio mantiene sus datos localmente.
- Se entrena un modelo común que aprende de patrones distribuidos.
- Se respetan las restricciones regulatorias y de gobernanza de datos.
Los resultados obtenidos han sido consistentes en distintos despliegues:
Detección de fraude
- Mejora de entre un 15% y un 25% en la tasa de detección de fraude, especialmente en tipologías emergentes.
- Reducción de falsos positivos en torno a un 10%, mejorando la experiencia del cliente.
- Capacidad de identificar patrones transversales entre países que no eran visibles de forma local.
Mejora de la conversión
- Incremento de la tasa de conversión comercial entre un 10% y un 20%, gracias a modelos de propensión más precisos.
- Mejor identificación de oportunidades de venta cruzada entre banca y seguros.
- Optimización de campañas mediante el uso de señales agregadas de múltiples mercados.
Retención de clientes
- Mejora de entre un 12% y un 18% en la predicción de abandono (churn).
- Incremento en la efectividad de campañas de retención.
- Identificación temprana de patrones de desafección del cliente que no eran detectables en datasets aislados.
Más allá de las métricas, el impacto estructural ha sido igualmente relevante:
- Las entidades han podido colaborar sin compartir datos sensibles, manteniendo el cumplimiento con el RGPD y regulaciones locales.
- Se han roto los silos de información sin comprometer la gobernanza del dato.
- Se ha establecido un modelo escalable para futuras iniciativas de inteligencia artificial colaborativa.
Este caso refleja cómo el aprendizaje federado permite a las organizaciones financieras maximizar el valor de sus datos manteniendo el control sobre los mismos, alineando innovación, cumplimiento normativo y estrategia de negocio.
En este nuevo contexto, el aprendizaje federado se consolida como una arquitectura de confianza para el desarrollo de sistemas de inteligencia artificial. Su valor no reside únicamente en permitir entrenar modelos sin centralizar los datos, sino en ofrecer un marco técnico que integra desde el diseño principios esenciales como la minimización, la seguridad, la gobernanza y el control sobre la información. La experiencia de Sherpa.ai en sectores como la salud y las finanzas demuestra que es posible desplegar casos de uso reales con impacto medible, mejorando la precisión de los modelos y habilitando nuevas formas de colaboración sin comprometer la privacidad. Este enfoque resulta especialmente relevante en el marco regulatorio europeo, al facilitar la aplicación práctica del RGPD, la privacidad desde el diseño y los principios del Reglamento Europeo de Inteligencia Artificial. En definitiva, el aprendizaje federado representa una vía sólida para avanzar hacia una IA más confiable, soberana y alineada con los derechos fundamentales.
Fuentes:
TechRadar: https://www.techradar.com/pro/how-dark-data-could-be-your-companys-downfall?
Los contenidos, opiniones o comentarios publicados en este sitio web son responsabilidad exclusiva de sus autores y no reflejan ni sustituyen las comunicaciones oficiales, visión o directrices de la AEPD.